Project overview
The lab uses a real telecom customer file where each row represents one account with service history, product bundle, billing behavior and a churn label. This raw table was transformed into a supervised learning pipeline that predicts churn and explains why some customers are at higher risk.
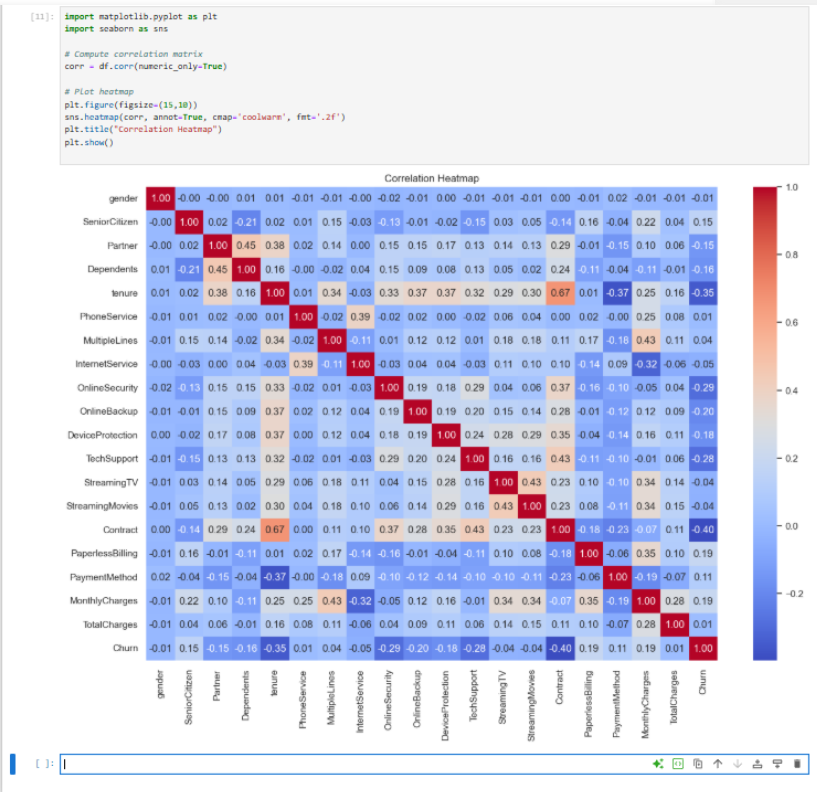
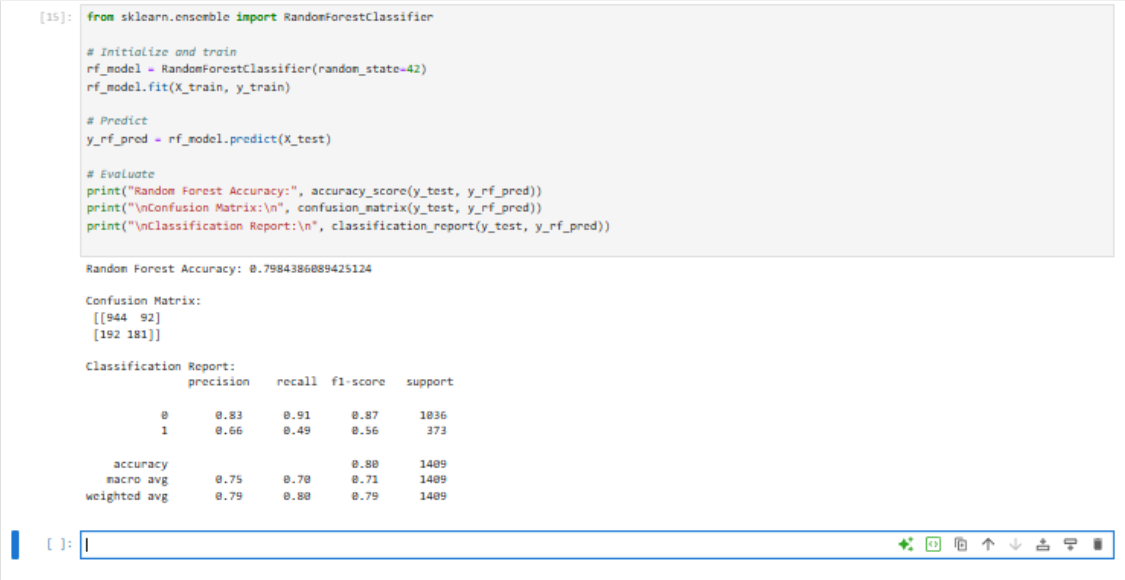
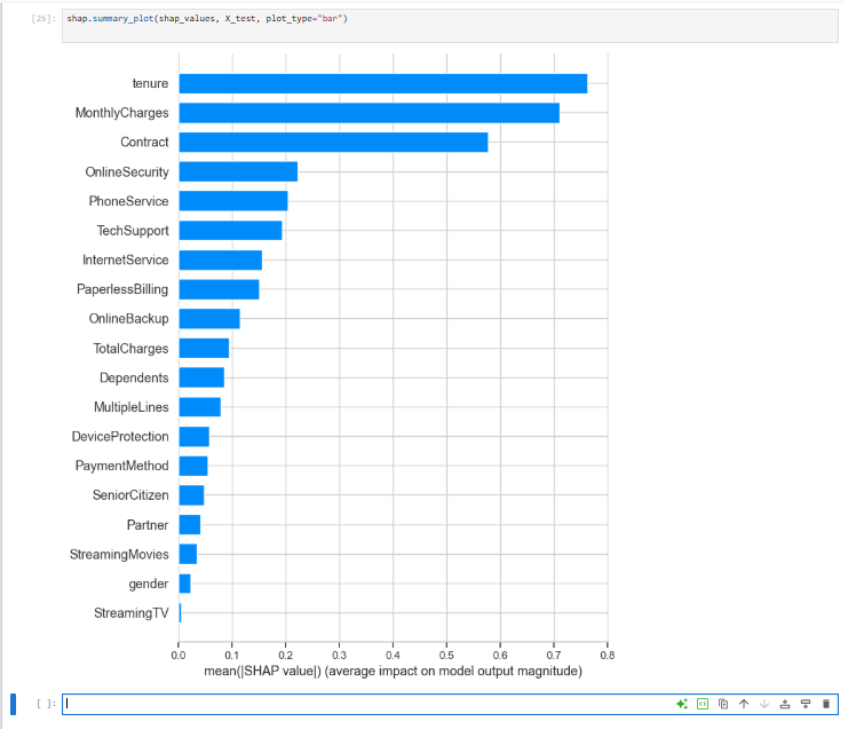
After cleaning billing fields and encoding plan details into numeric features, a Random Forest classifier was trained and its performance was compared to a logistic baseline. SHAP values then translated model output into a ranked list of churn drivers that can feed marketing and service playbooks.