Project overview
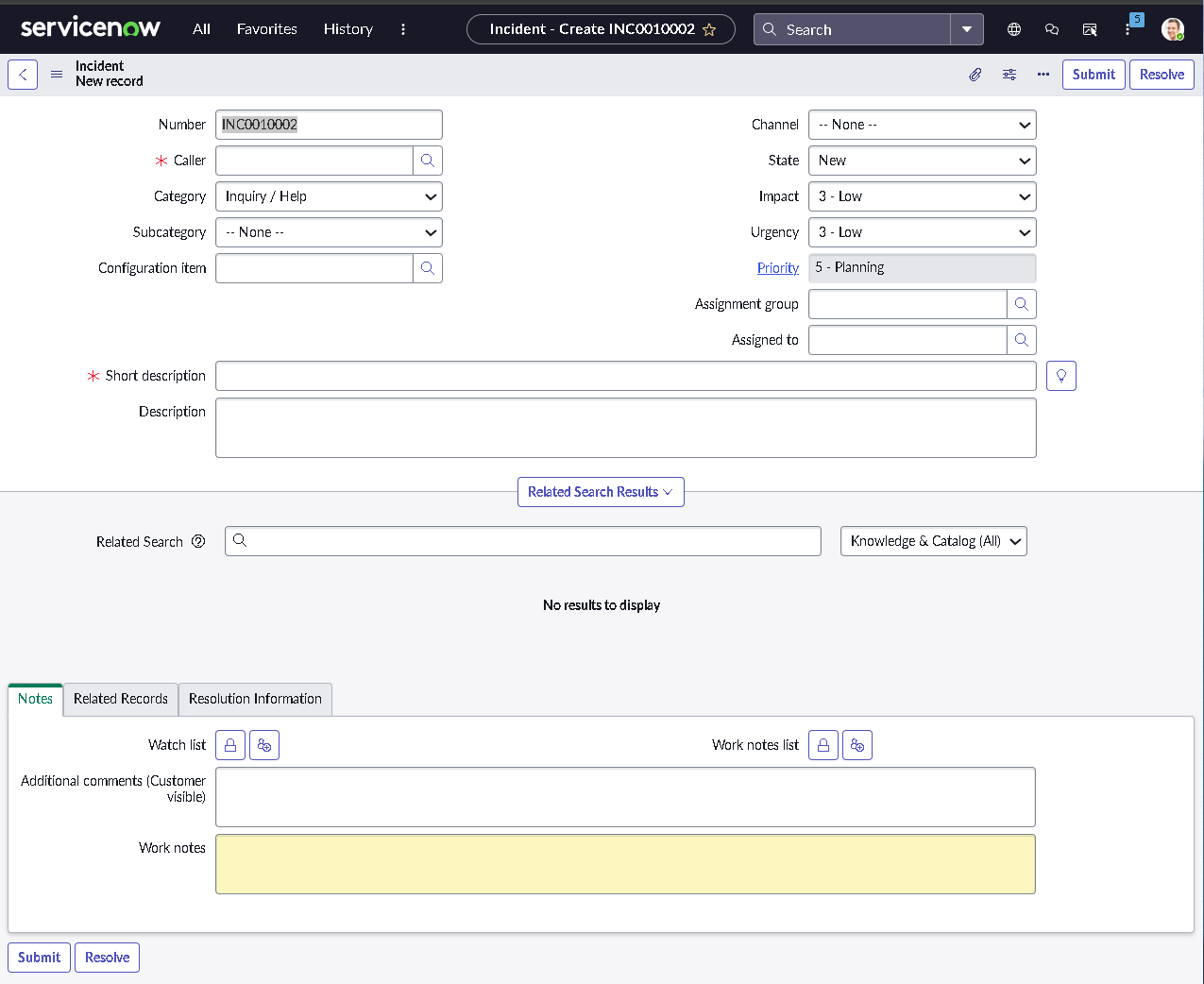
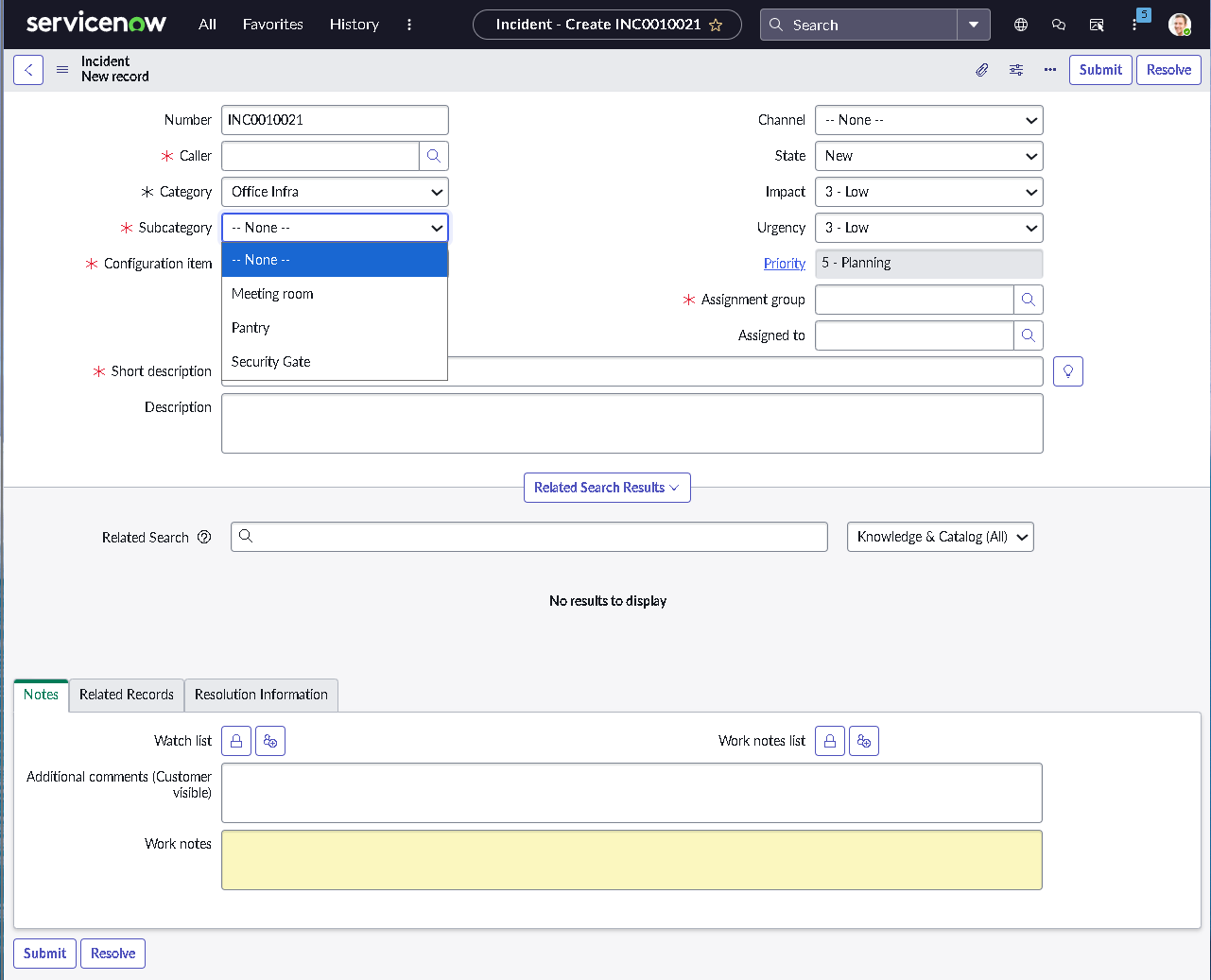
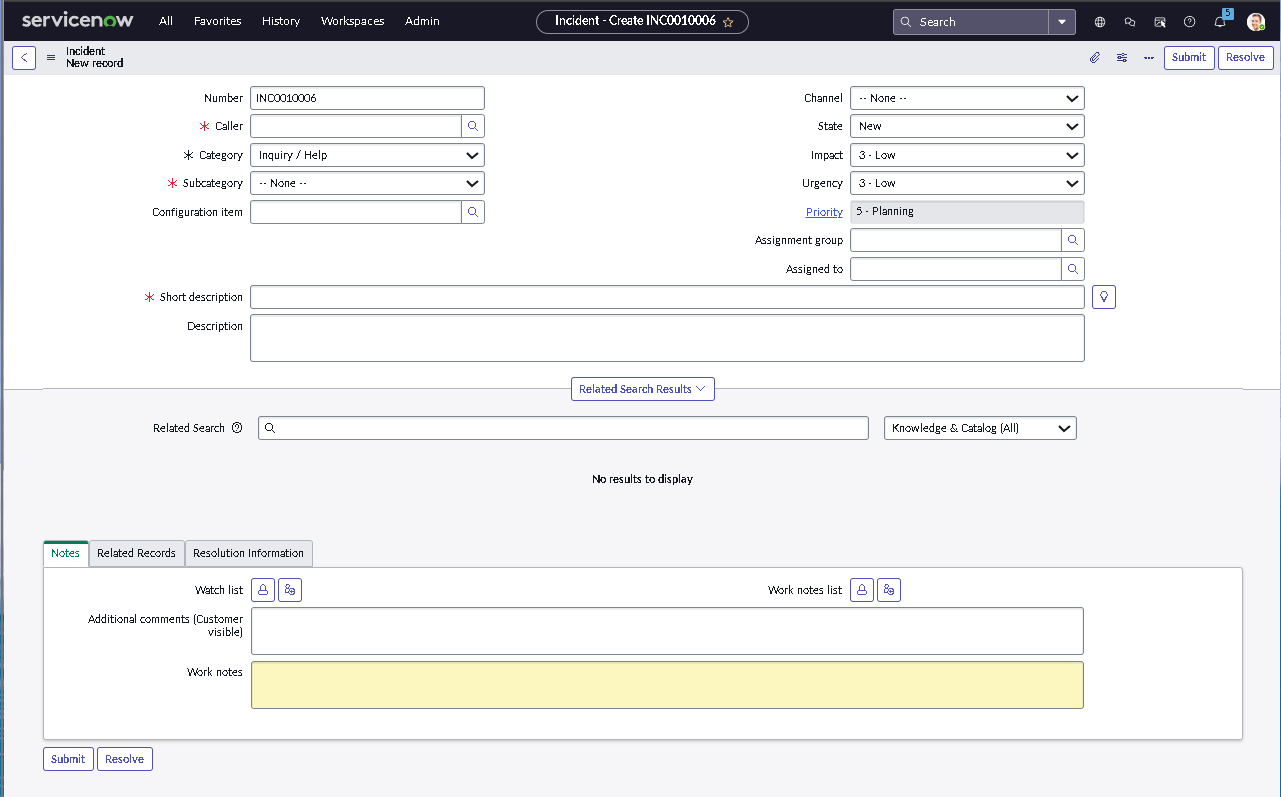
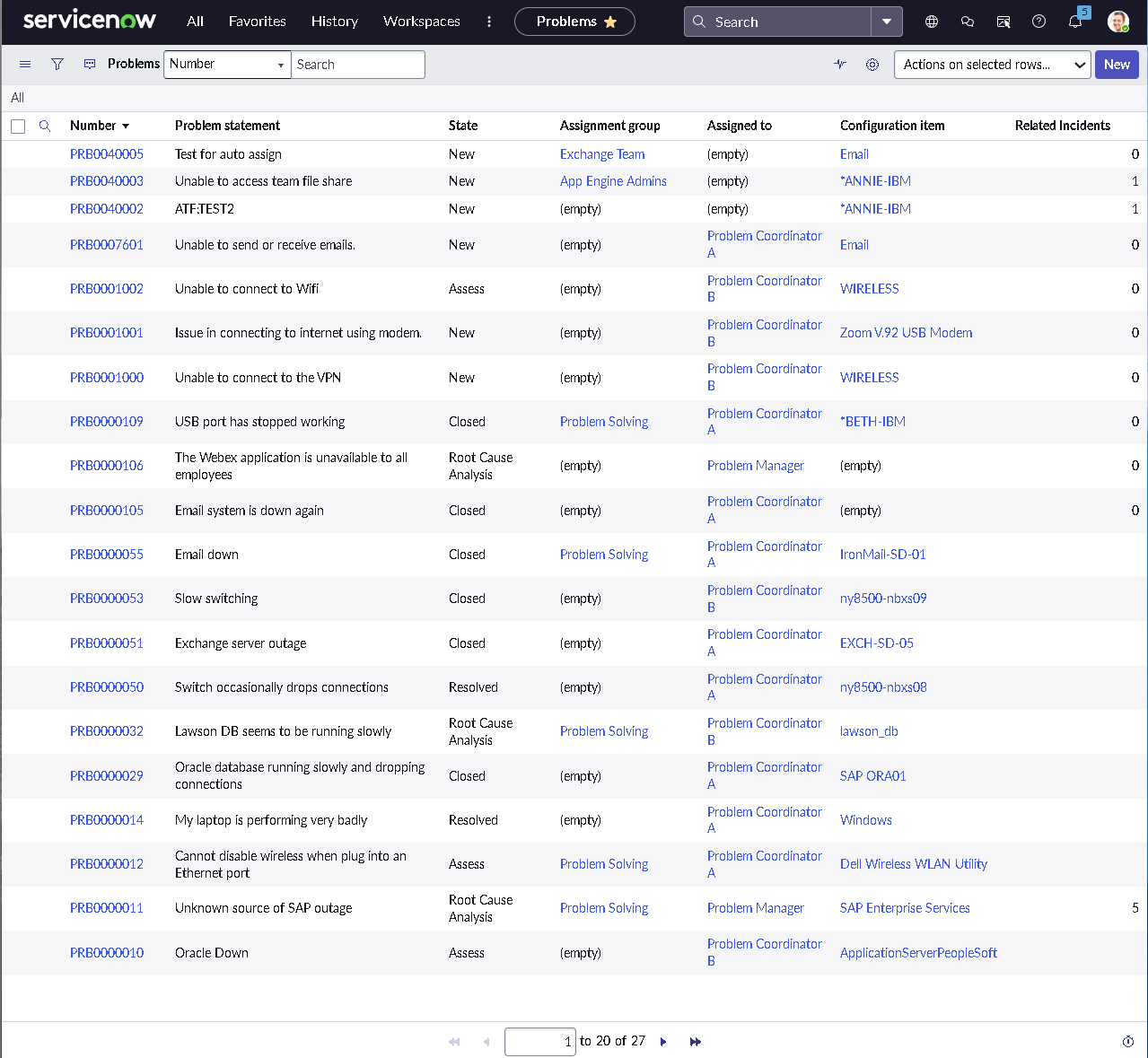
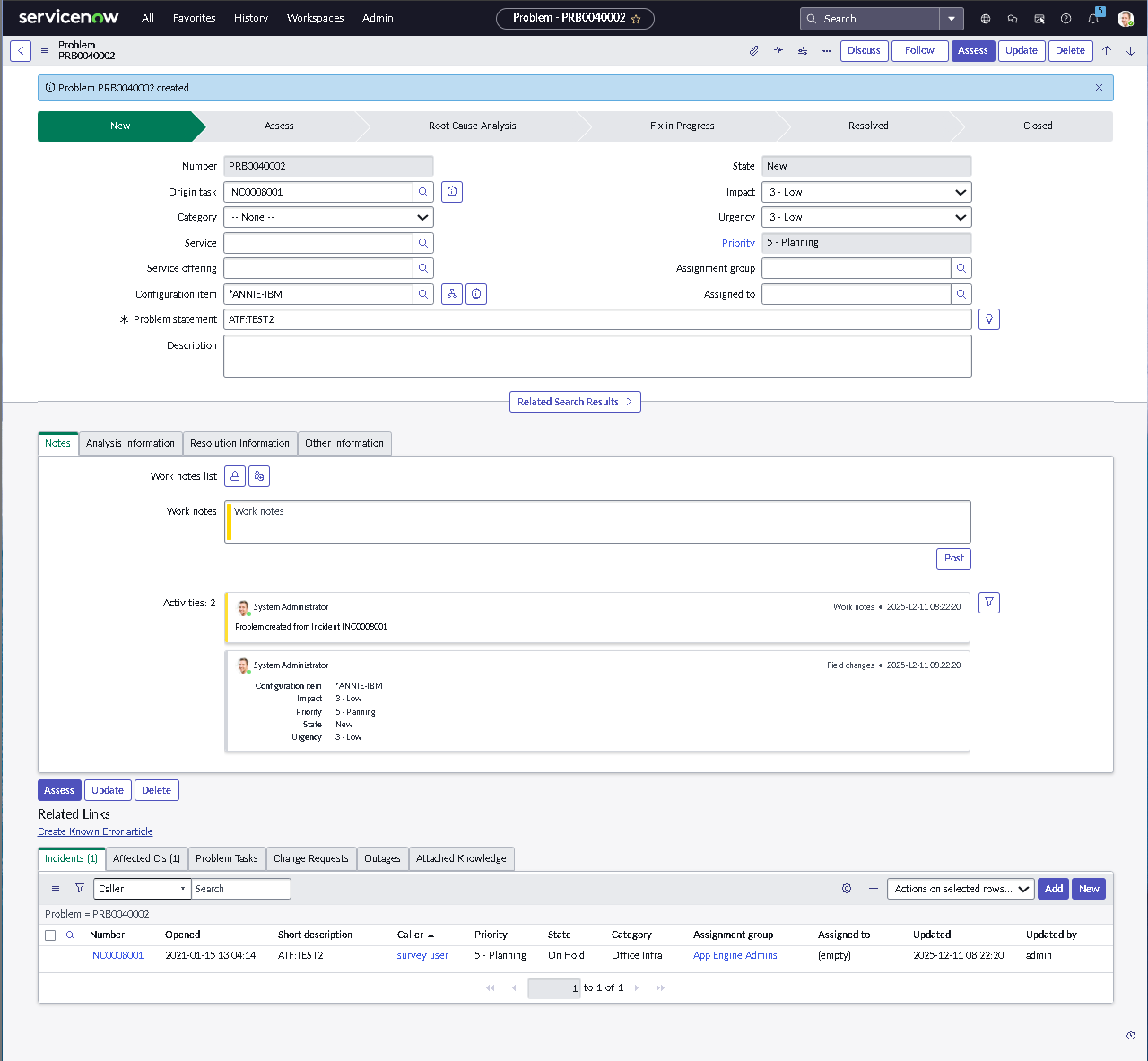
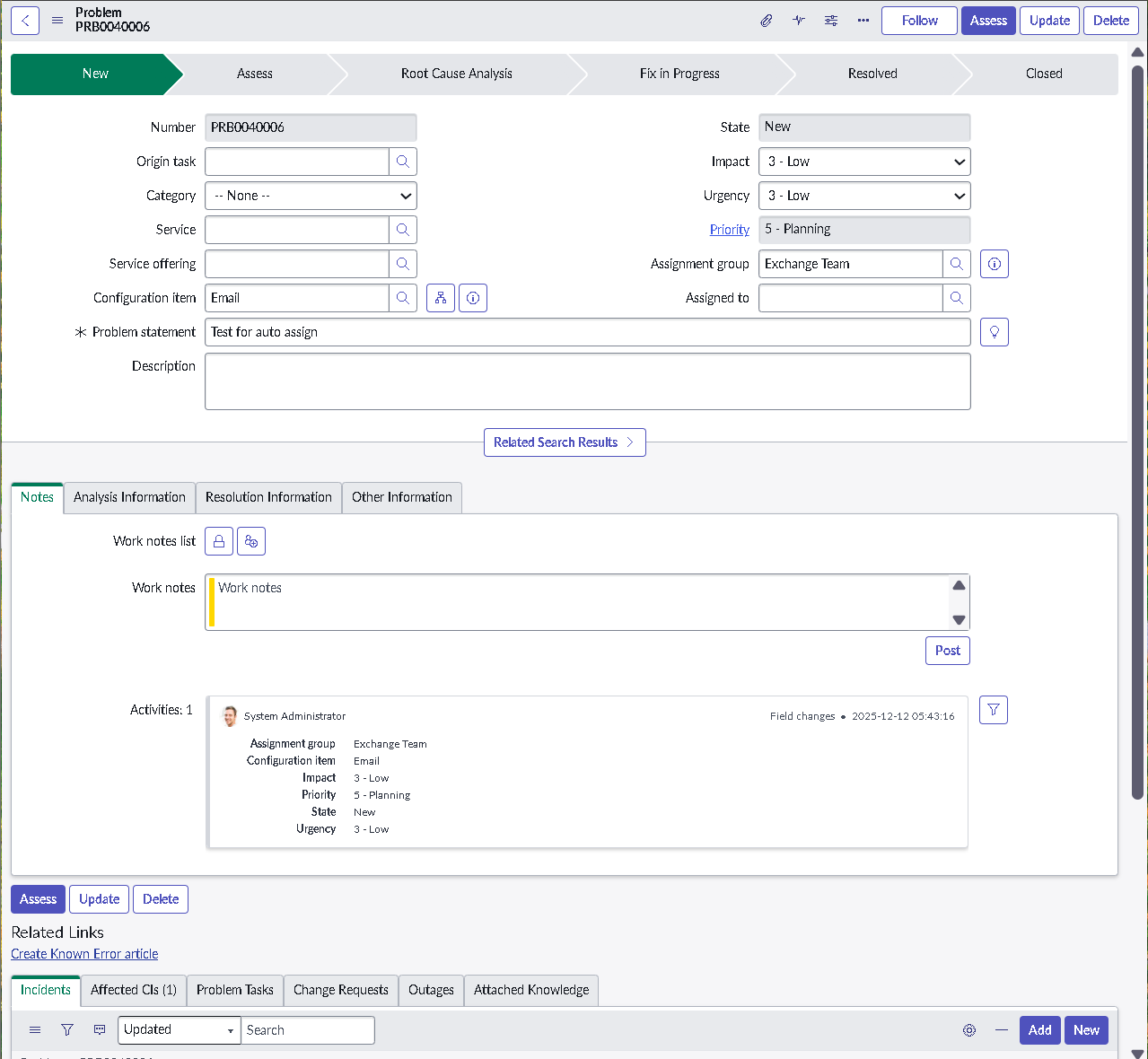
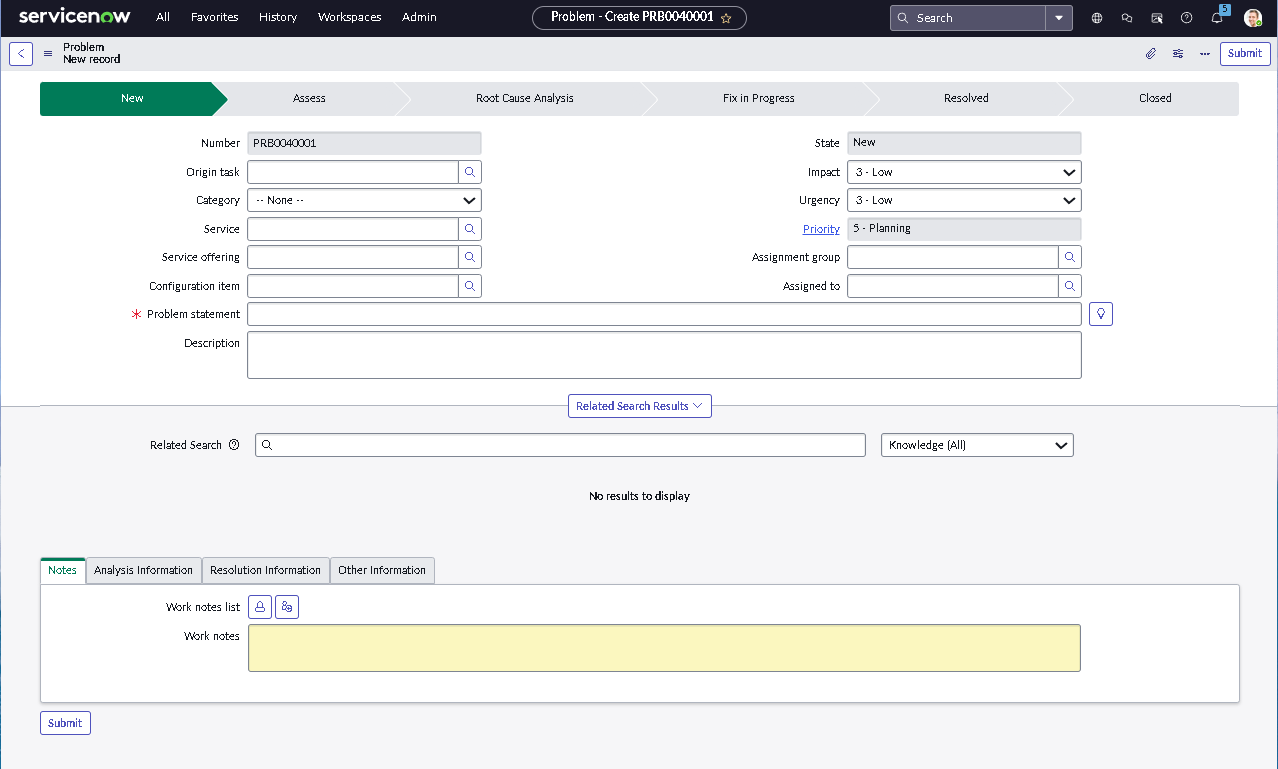
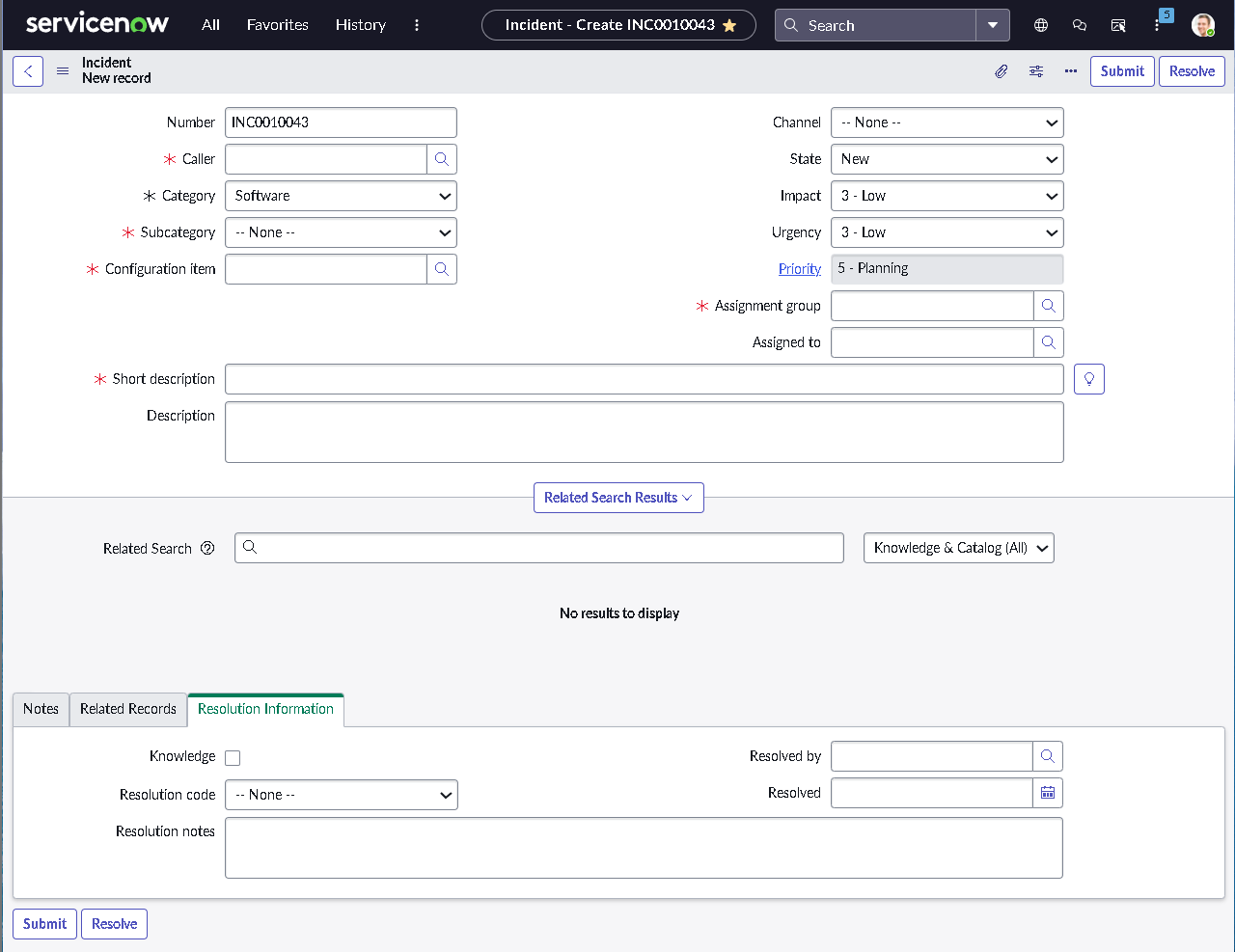
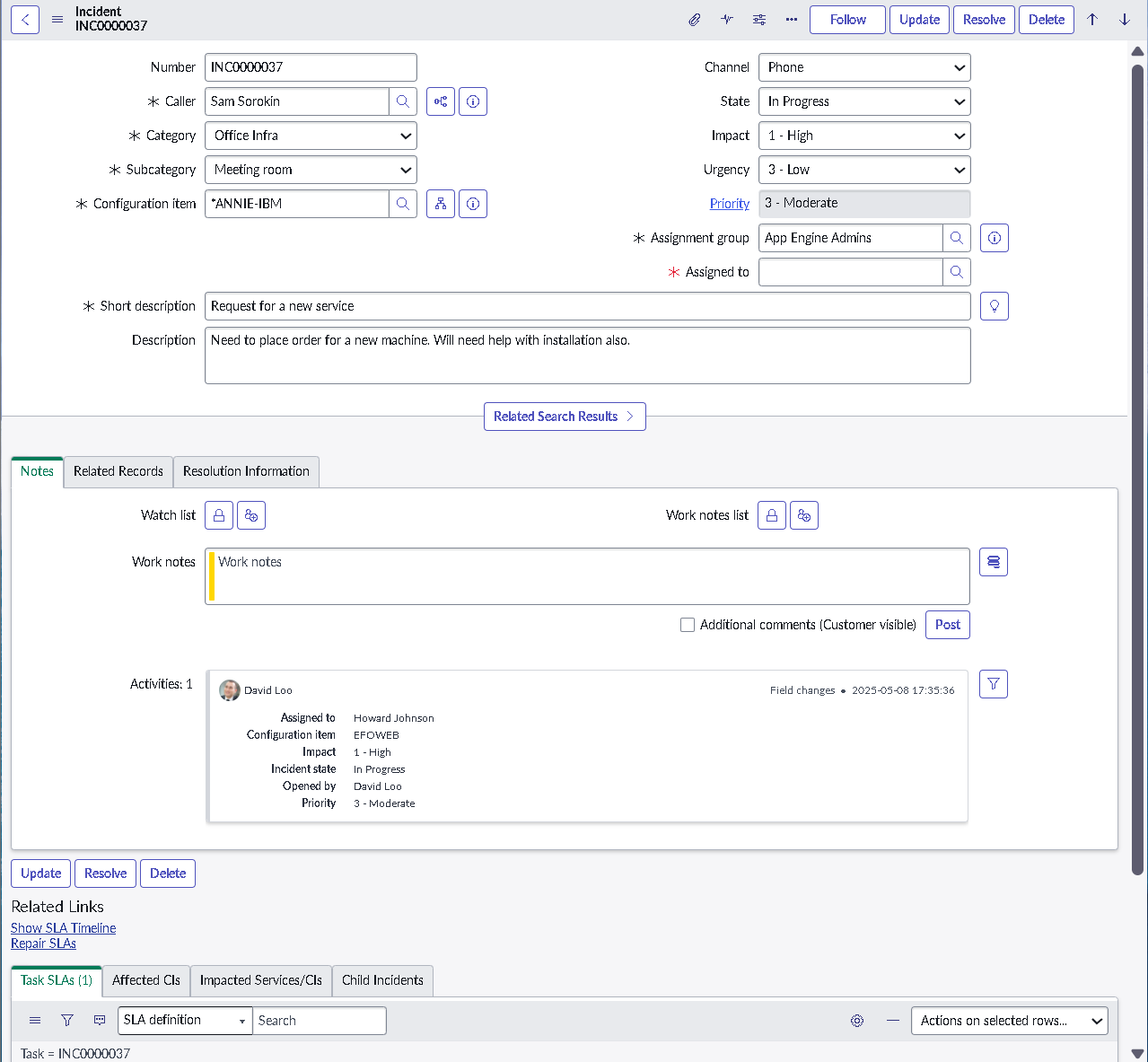
This lab simulates an ITSM implementation you would build during platform onboarding or process modernization. Instead of isolated features, the focus is on how pieces work together: structured forms, clean classification, predictable state changes, disciplined routing, and governance that prevents bad changes from slipping into production.
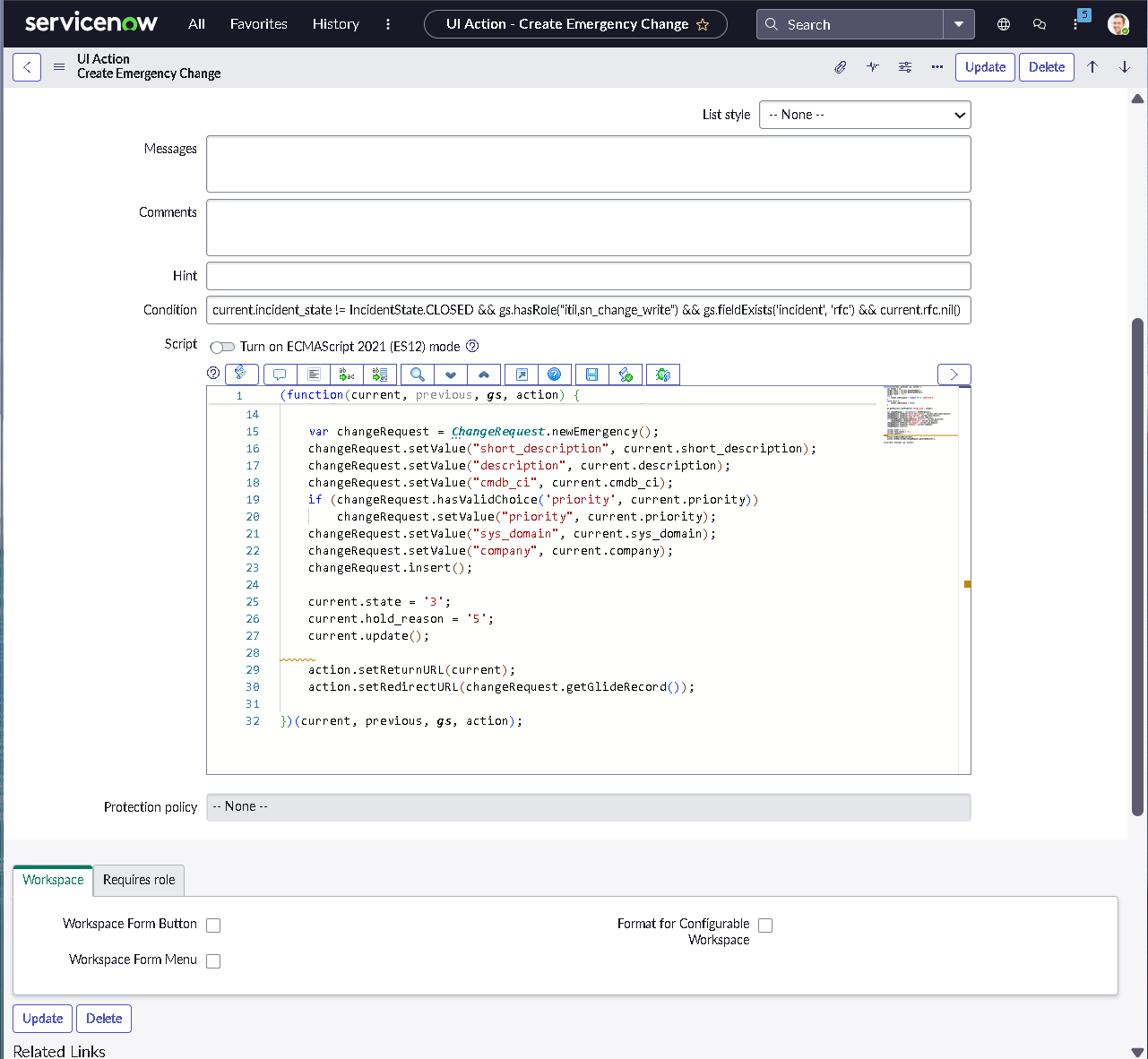
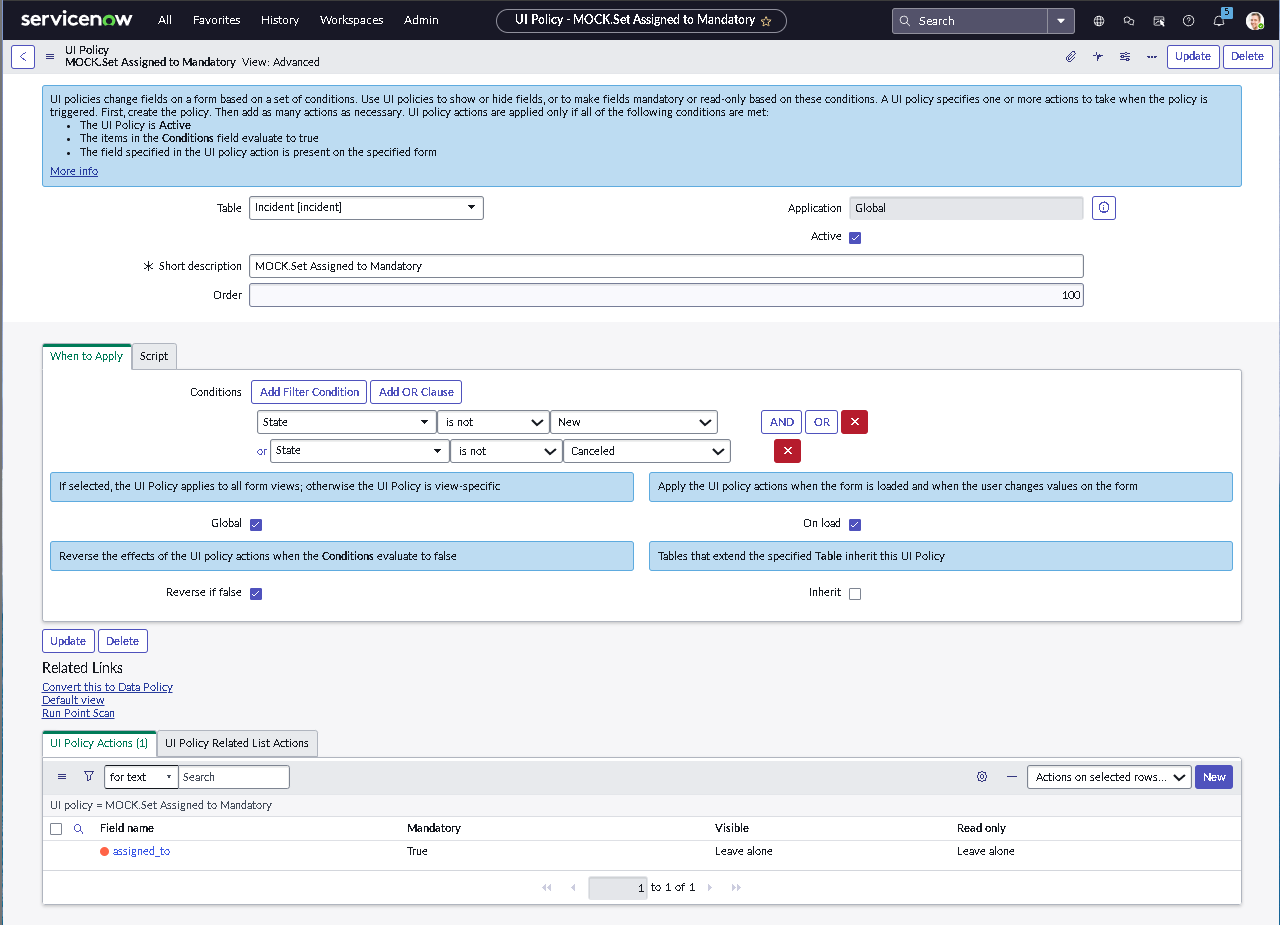
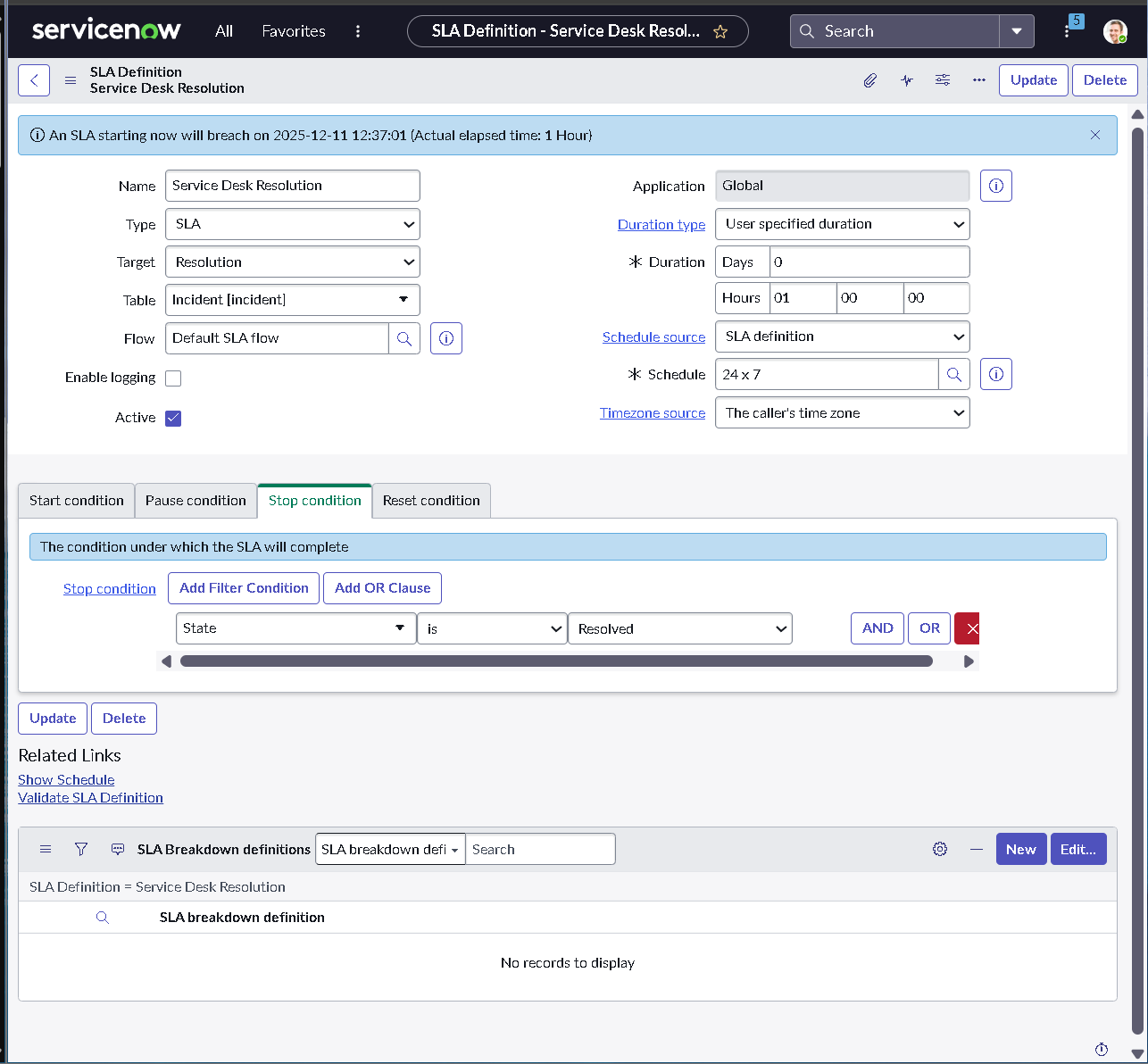
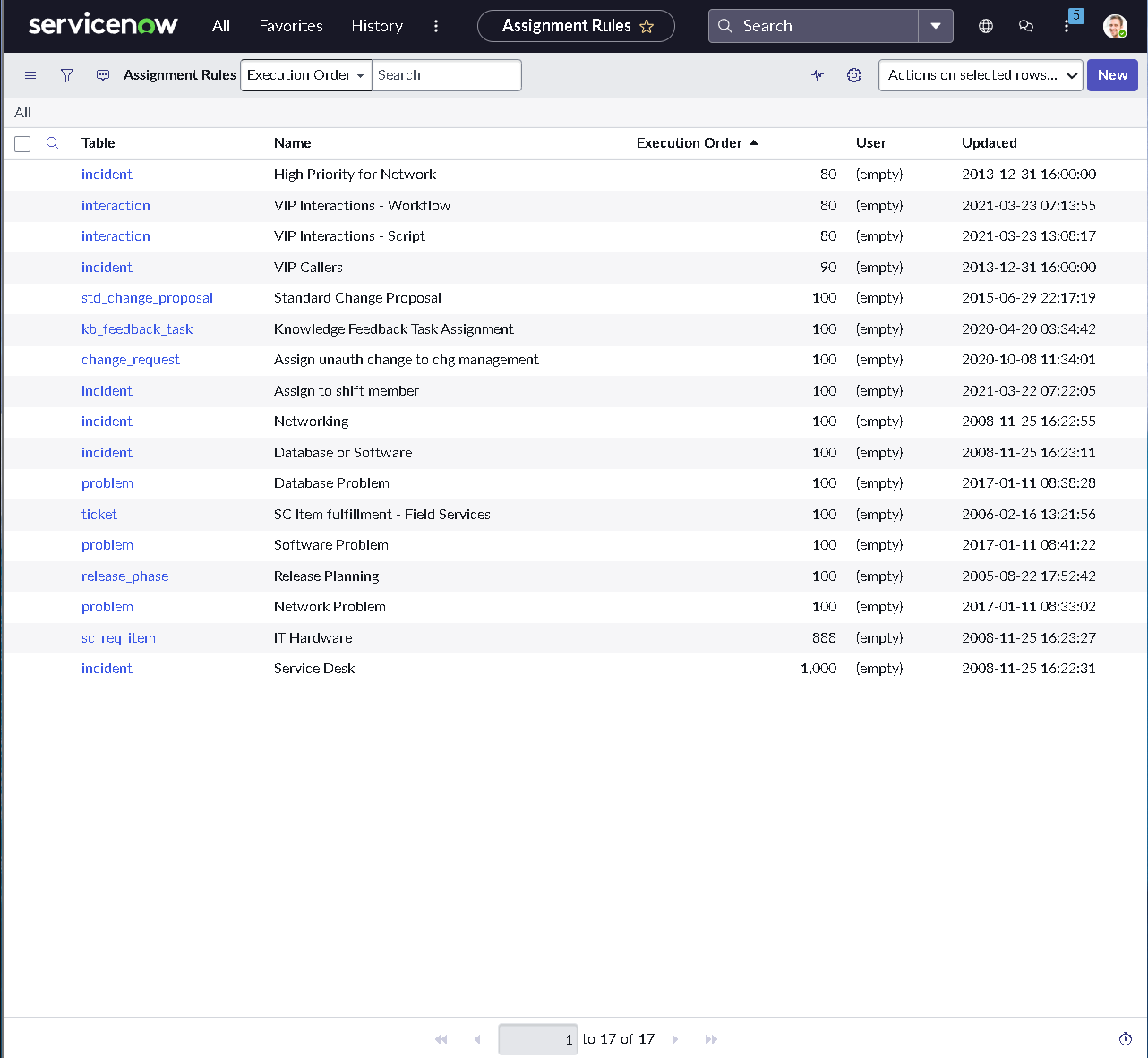
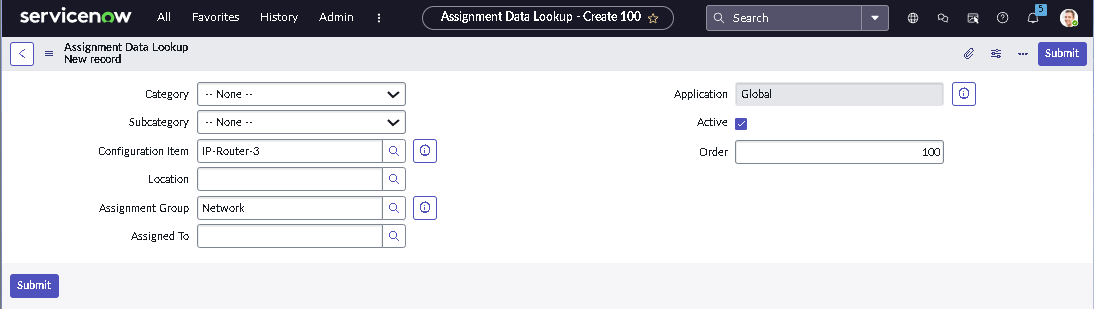
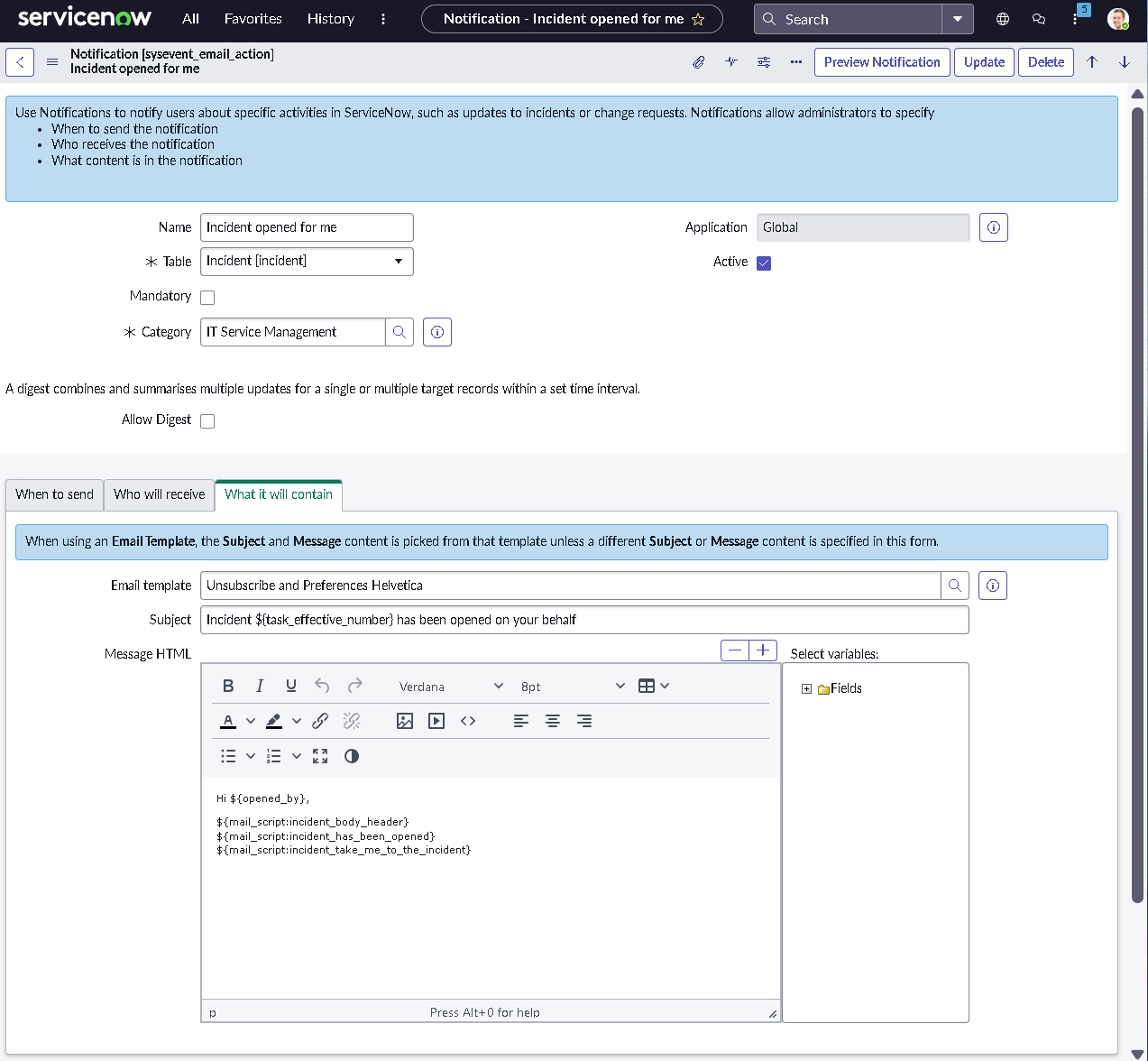
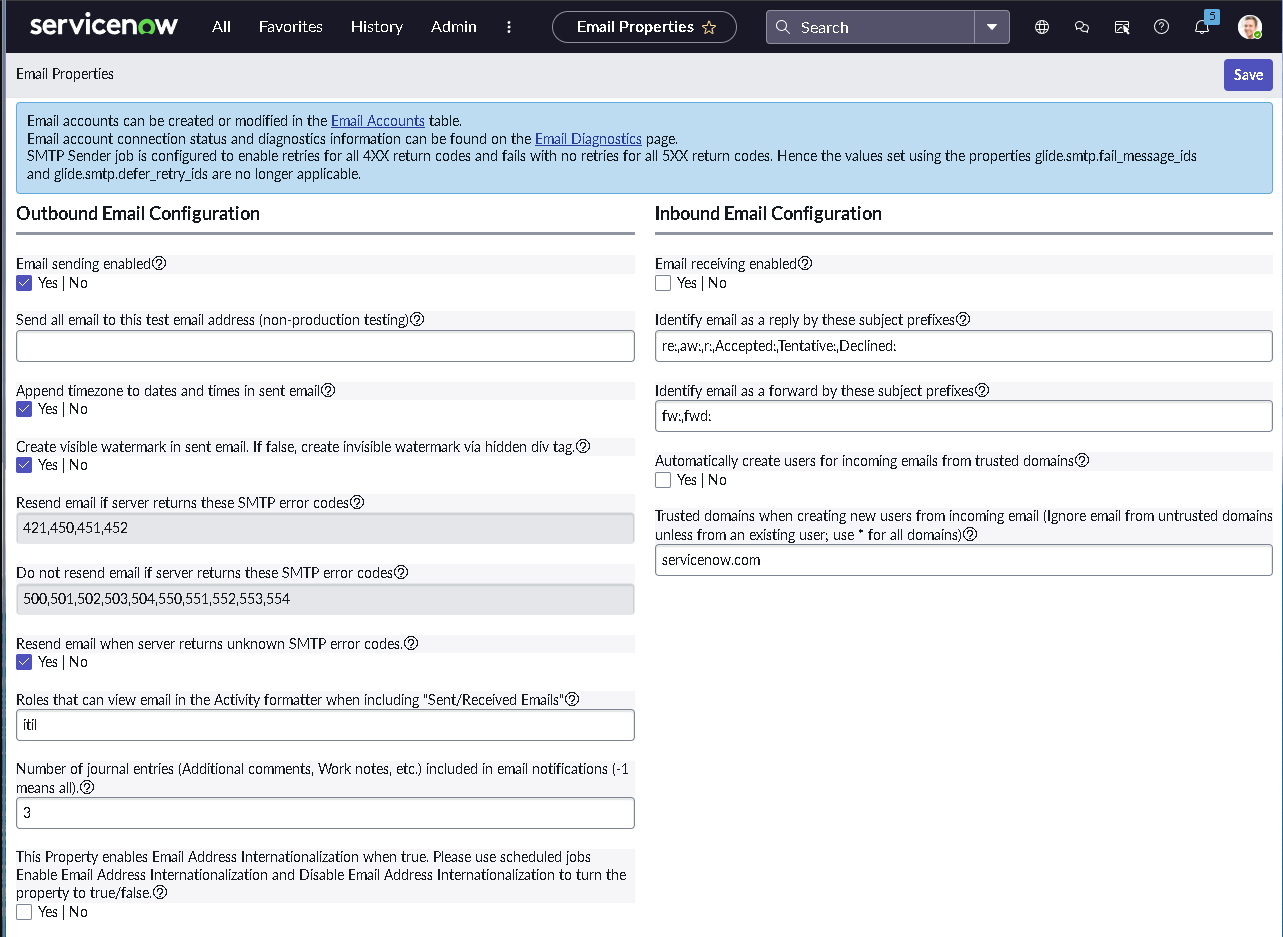
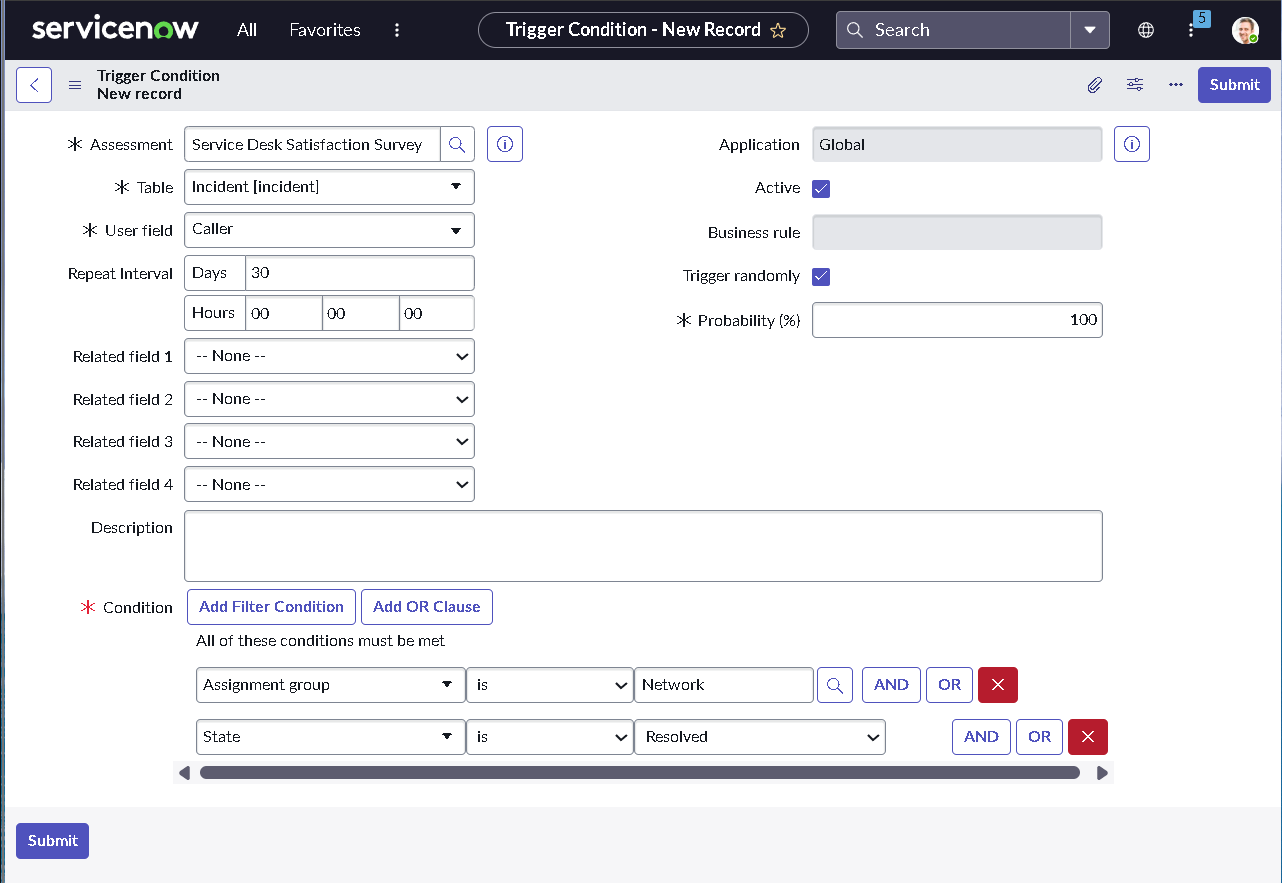
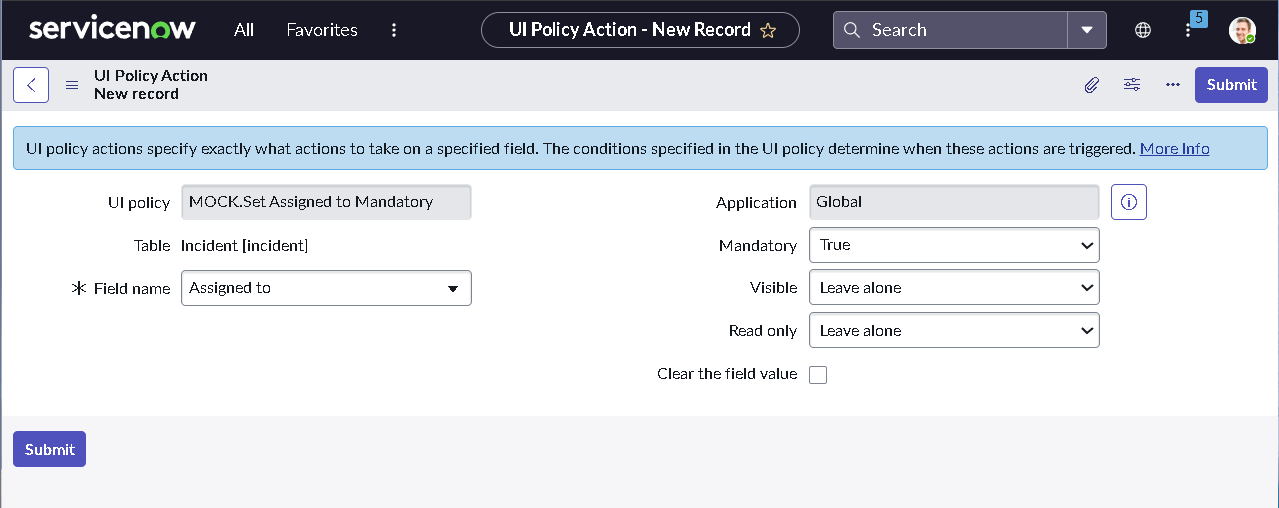
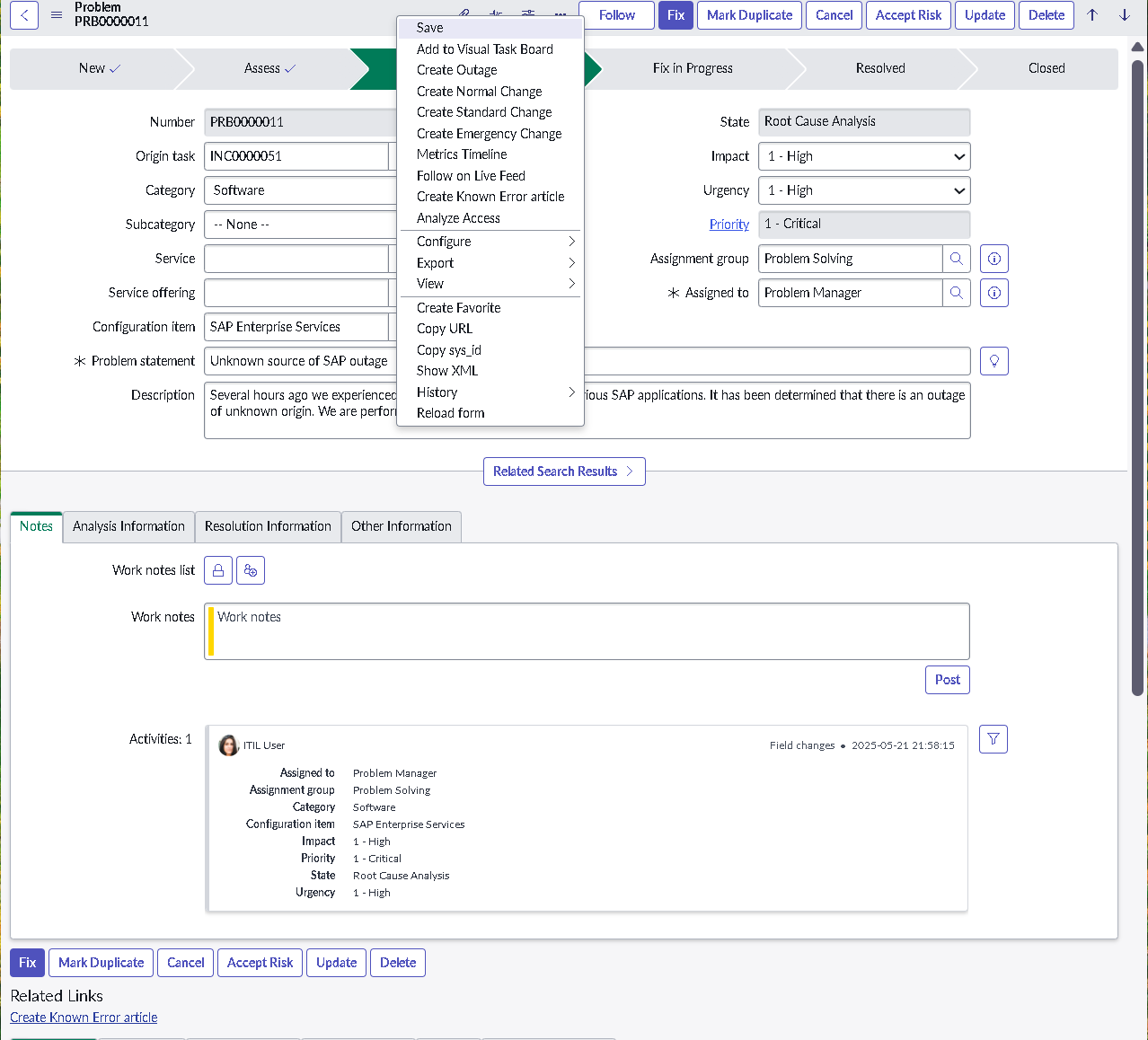
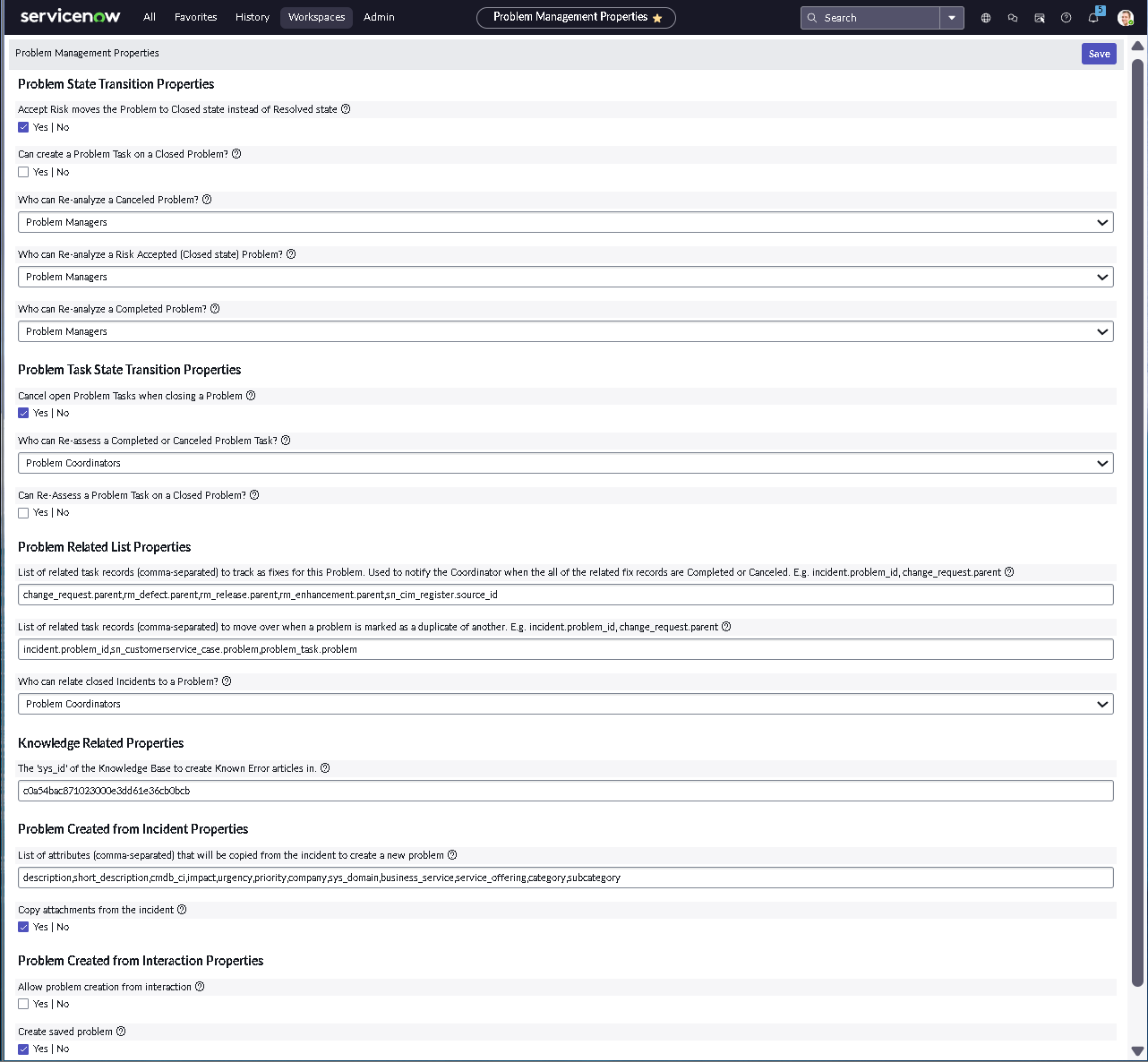
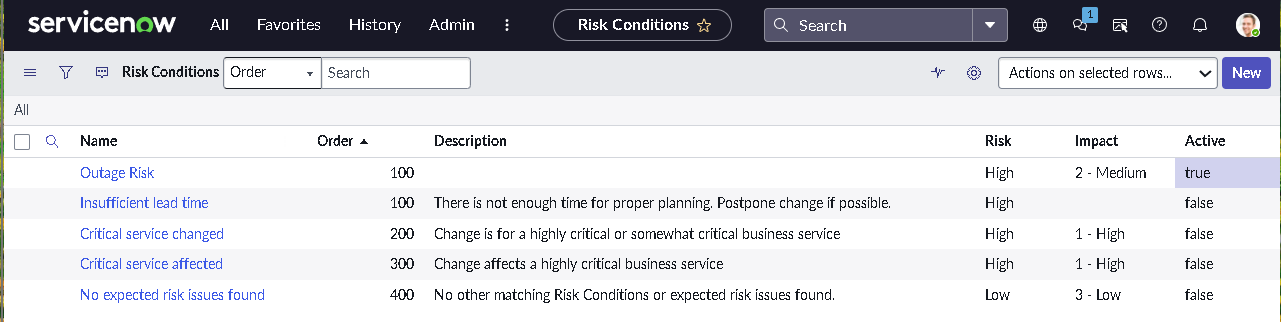
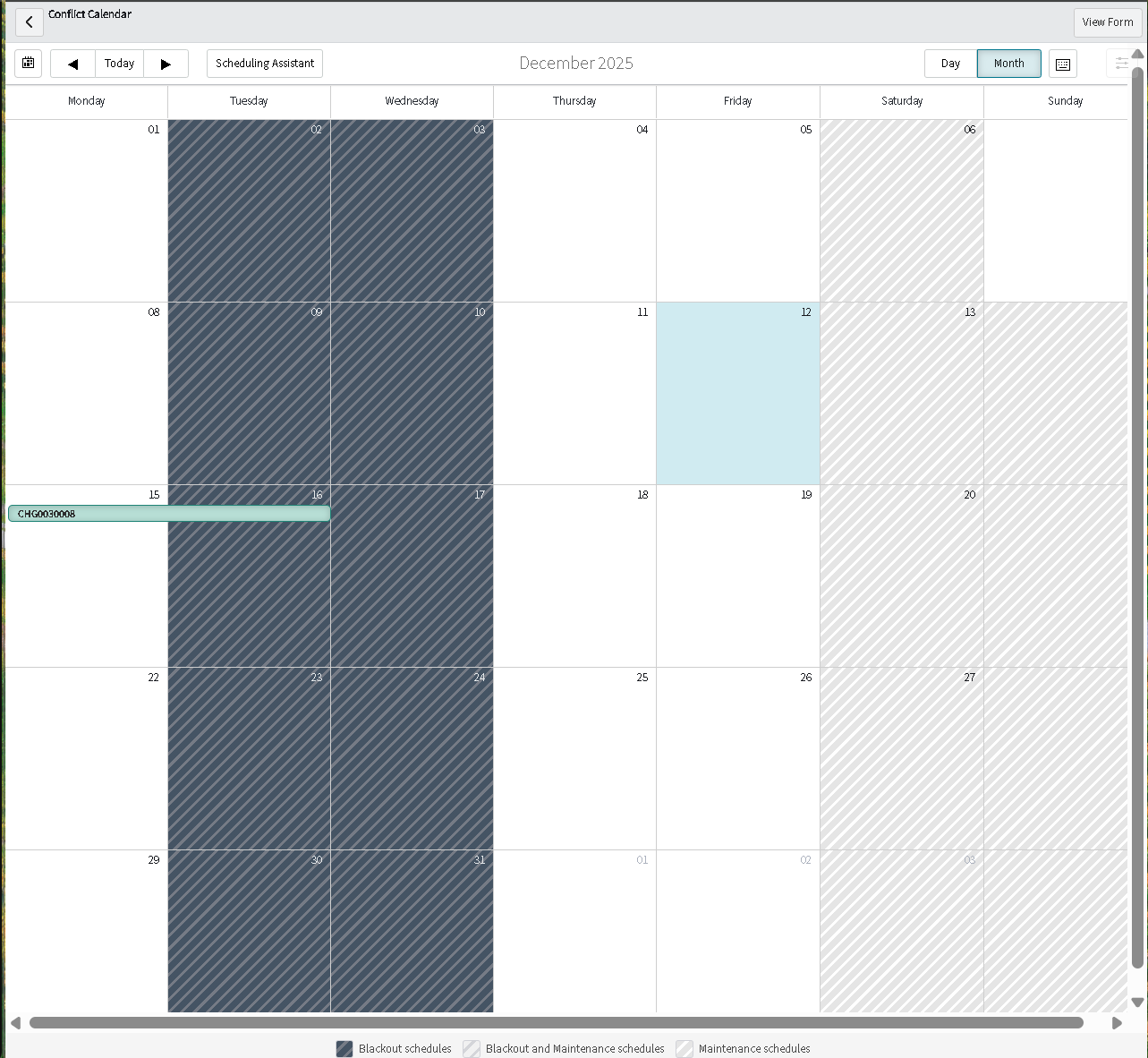
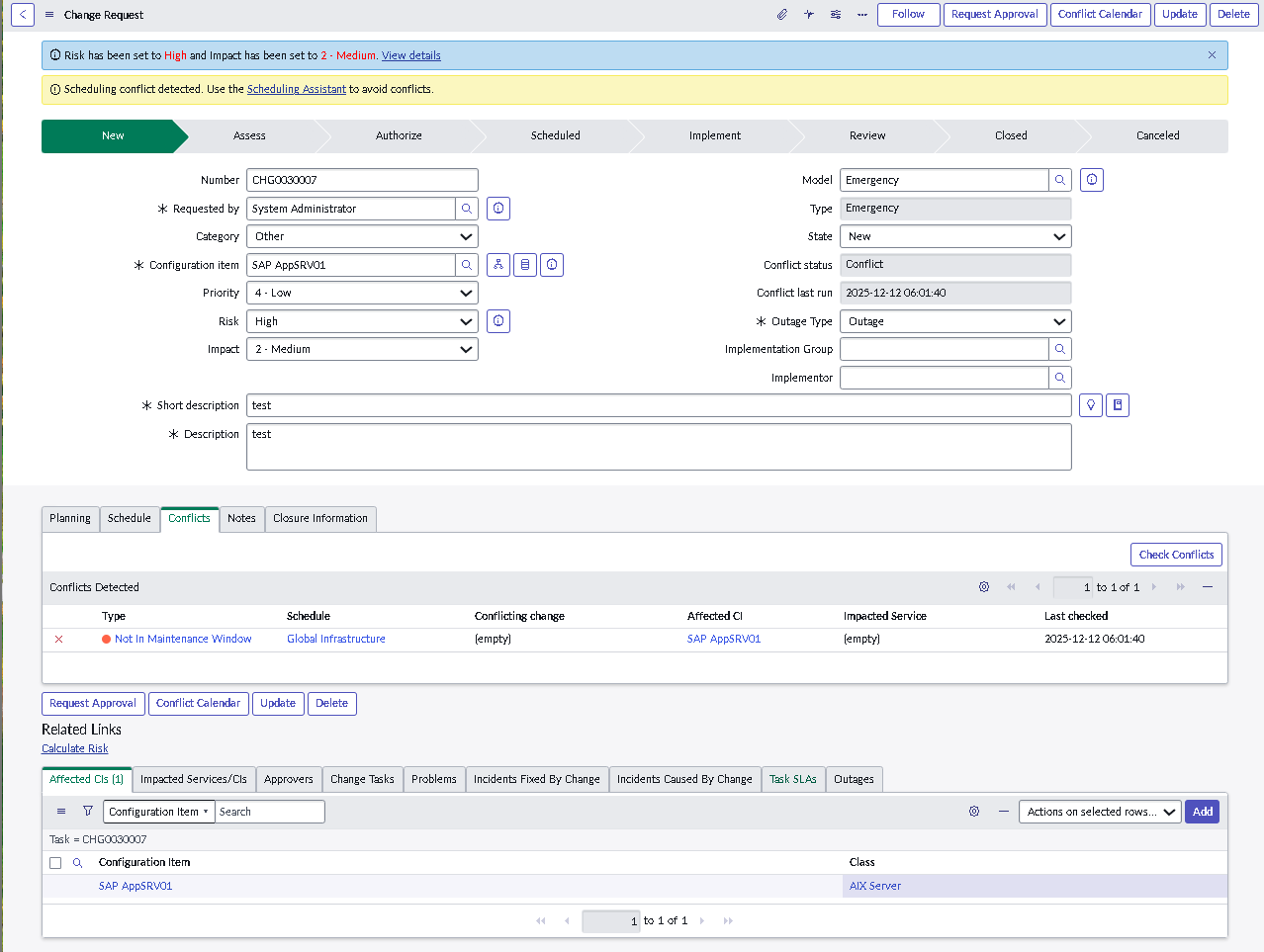
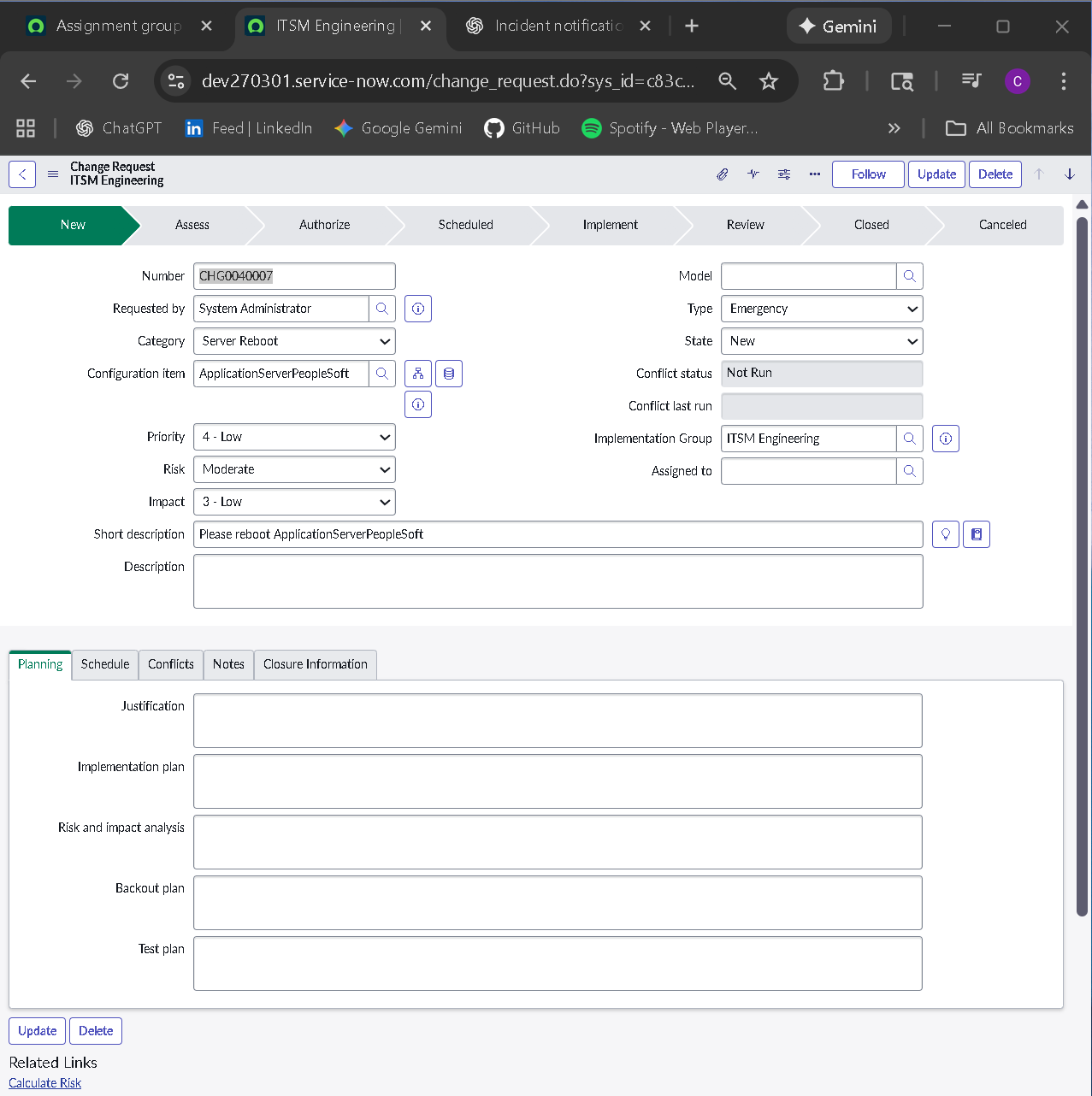
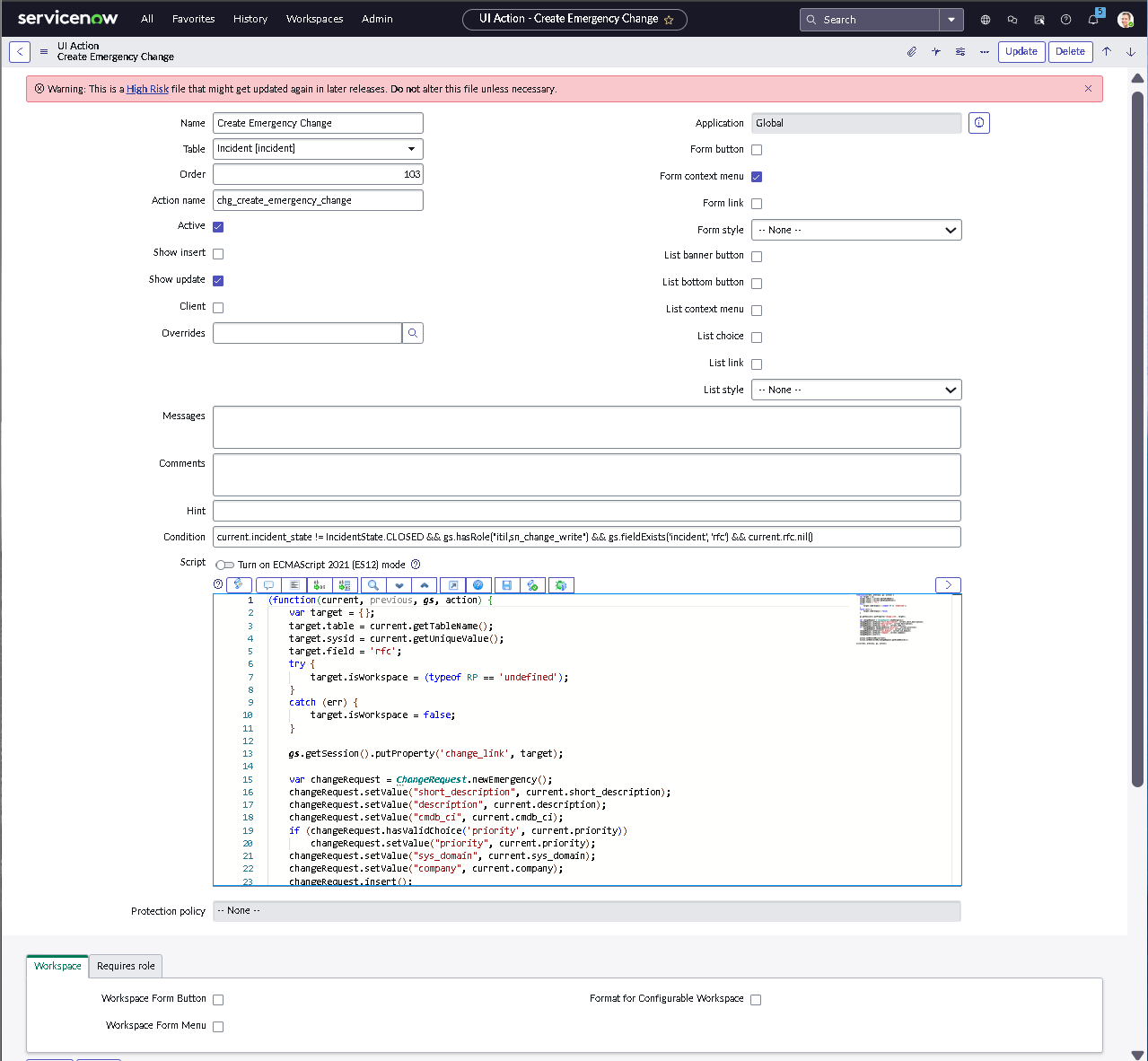
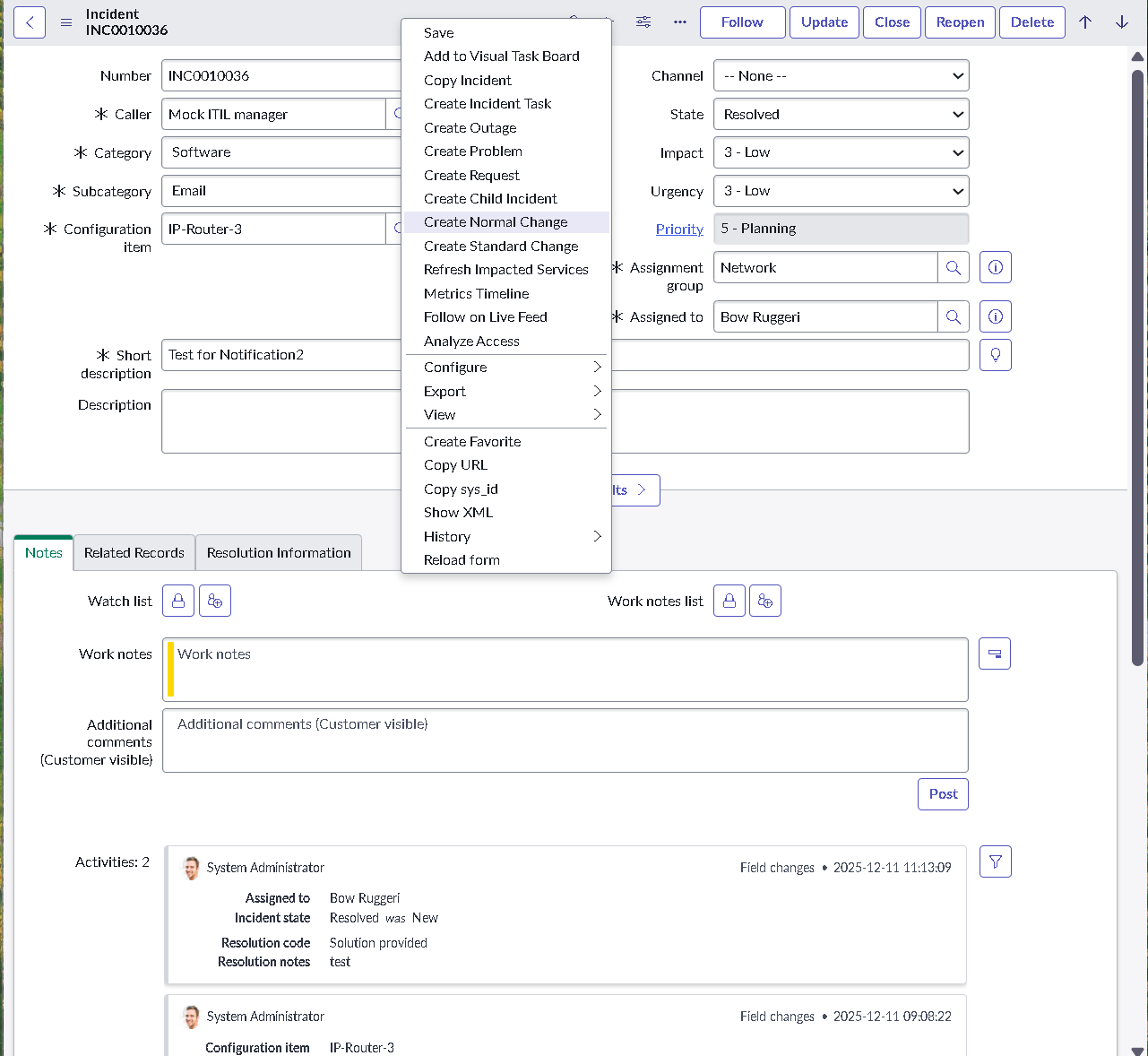
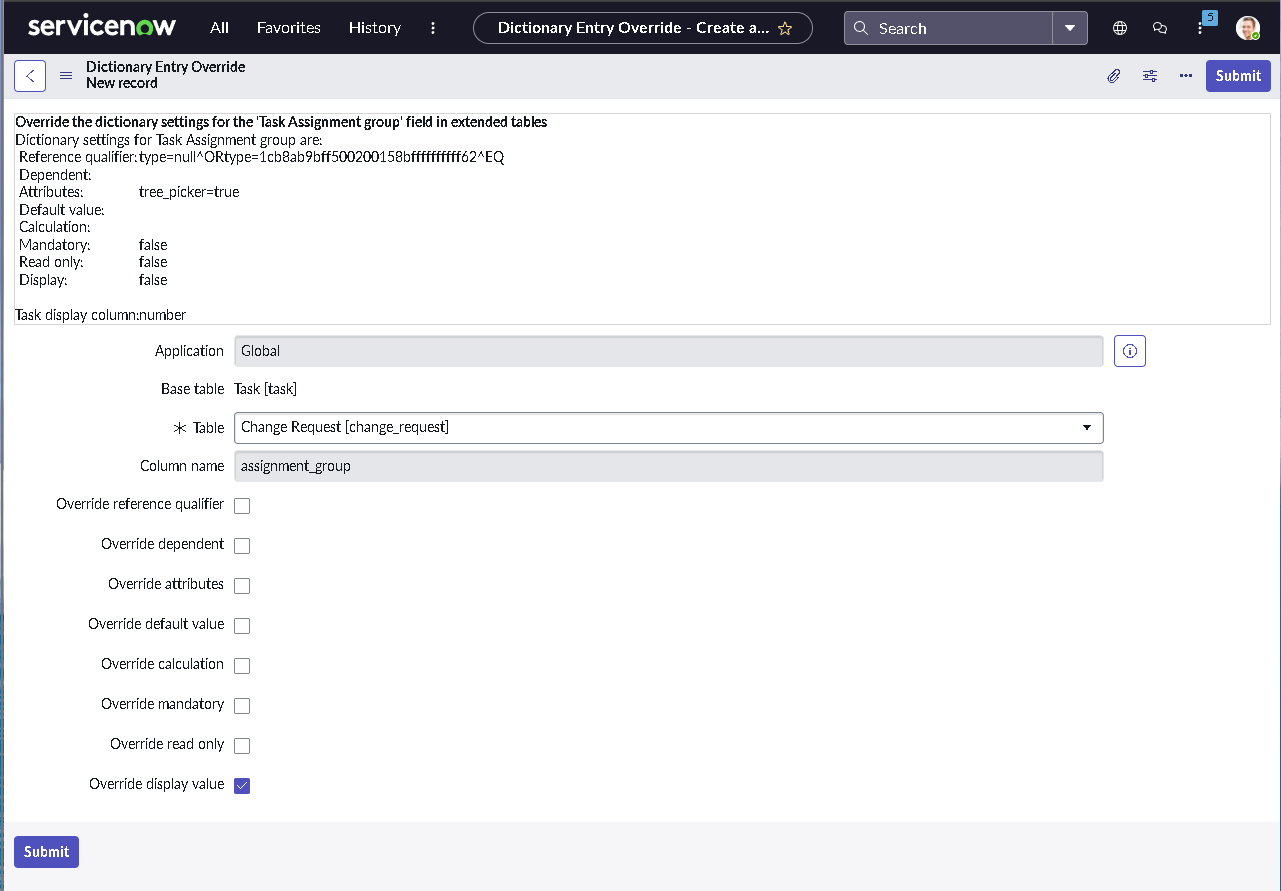
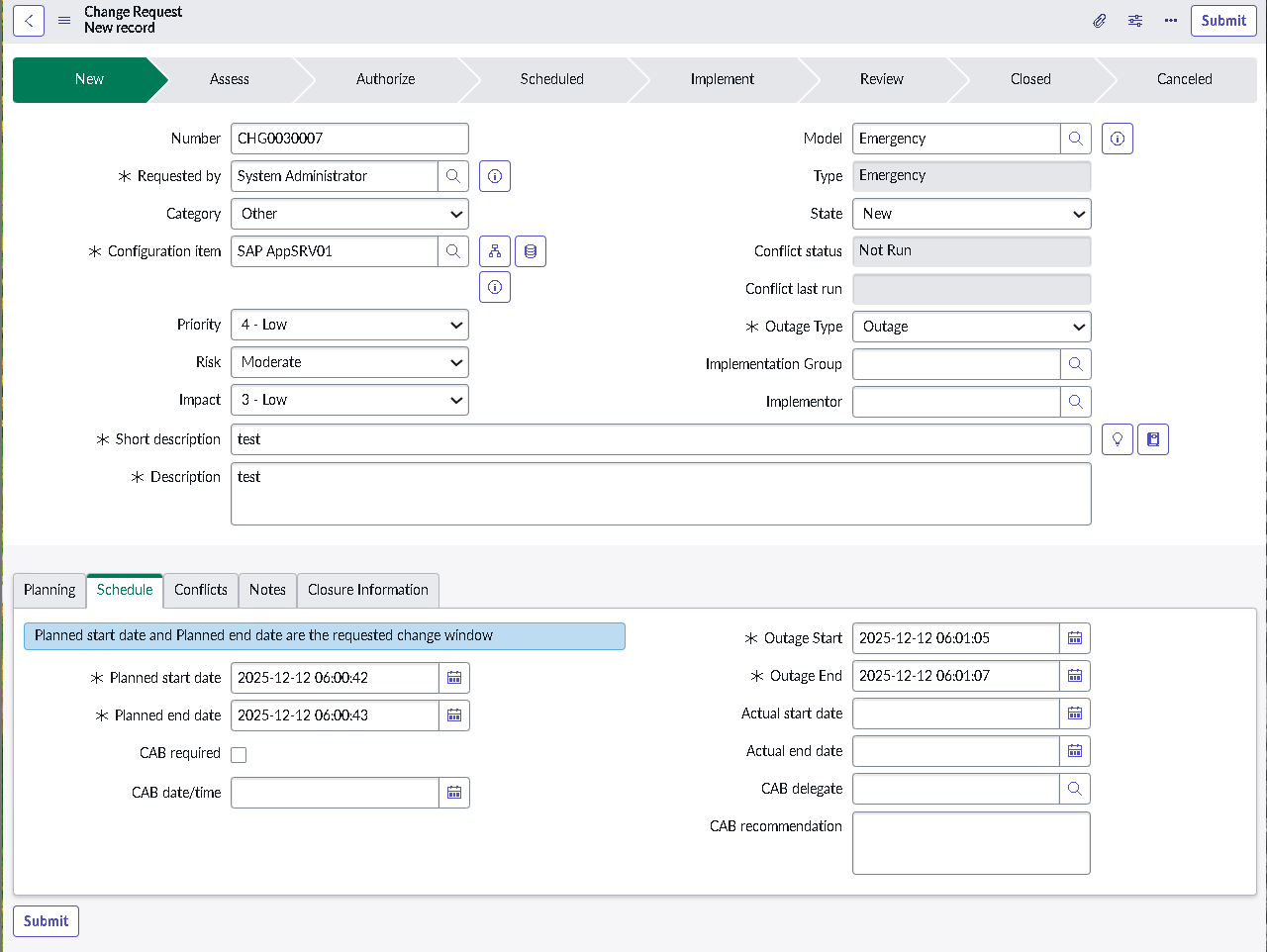
The implementation intentionally avoids custom scripting so the configuration mirrors how many regulated teams operate: using dictionary settings, UI policies, assignment rules, notifications, maintenance schedules, blackout windows, and controlled UI actions.